
Crawl là gì? Chi tiết về quá trình thu thập dữ liệu Google
- SEO
- 18 July, 2025
Bạn có bao giờ tự hỏi, làm thế nào mà chỉ sau vài giây gõ tìm kiếm, Google đã có thể trả về hàng triệu kết quả cho bạn? Phía sau màn hình ấy là một cuộc hành trình thầm lặng nhưng vô cùng phức tạp của những “cỗ máy săn lùng” dữ liệu hay còn gọi là quá trình Crawl.
Hiểu đúng về Crawl là gì và cách Google thu thập dữ liệu sẽ giúp bạn không chỉ nắm bắt cách Internet vận hành, mà còn biết cách đưa website của mình “lọt vào mắt xanh” của Google nhanh hơn. Hãy cùng SEO Google Giá Rẻ khám phá chi tiết hành trình thám hiểm đầy thú vị này ngay trong bài viết dưới đây!
Crawl là gì?
Crawl là thuật ngữ chỉ quá trình mà các công cụ tìm kiếm như Google sử dụng để thu thập dữ liệu từ các trang web trên Internet. Nói đơn giản, “crawl” giống như việc một con robot hay còn gọi là crawler đi từ trang này sang trang khác, đọc nội dung, thu thập thông tin, và đưa dữ liệu đó vào hệ thống của công cụ tìm kiếm.
Trong thế giới SEO, crawl là bước đầu tiên và bắt buộc để một website có cơ hội xuất hiện trên kết quả tìm kiếm. Nếu trang web của bạn không được Google crawl, thì dù nội dung có hay đến đâu, nó vẫn “vô hình” đối với người dùng tìm kiếm trên Google.
Phân biệt Crawl, Index và Rank
Để hiểu rõ hơn, cần phân biệt ba khái niệm quan trọng:
- Crawl: Là quá trình Googlebot truy cập, đọc và thu thập dữ liệu trang web.
- Index: Là việc Google lưu trữ và tổ chức dữ liệu đã crawl được vào hệ thống dữ liệu của mình. Một trang chỉ có thể được xếp hạng nếu đã được index.
- Rank: Là quá trình Google đánh giá, sắp xếp các trang web đã index dựa trên hàng trăm tiêu chí, để hiển thị chúng theo thứ tự phù hợp nhất với truy vấn tìm kiếm.
Tóm lại: Không crawl → Không index → Không rank. Quá trình crawl chính là cánh cửa đầu tiên mở ra cơ hội tiếp cận người dùng cho bất kỳ website nào.
Crawler (Bot) của Google là gì?
Crawler hay còn gọi là bot tìm kiếm là những chương trình tự động do các công cụ tìm kiếm, như Google, phát triển để thực hiện quá trình crawl. Những bot này liên tục lướt web, khám phá các trang mới, cập nhật nội dung trang cũ, và gửi dữ liệu thu thập được về máy chủ của Google.

Trong hệ sinh thái của Google, Googlebot là tên gọi phổ biến nhất cho nhóm crawler này.
Các loại Googlebot hiện nay
Google không chỉ có một loại bot duy nhất. Để tối ưu việc thu thập dữ liệu trên nhiều thiết bị và định dạng nội dung khác nhau, Google đã phát triển nhiều loại bot chuyên biệt, bao gồm:
- Googlebot Desktop: Chuyên crawl các trang web dưới góc nhìn của trình duyệt máy tính.
- Googlebot Smartphone: Crawl website từ góc độ thiết bị di động, cực kỳ quan trọng trong thời đại Mobile-First Indexing hiện nay.
- Googlebot Image: Thu thập hình ảnh để phục vụ Google Images.
- Googlebot Video: Thu thập dữ liệu liên quan đến nội dung video.
- AdsBot: Đánh giá trang đích trong chiến dịch quảng cáo Google Ads.
Mỗi loại Googlebot có những nhiệm vụ riêng, nhưng tất cả đều hoạt động nhằm đảm bảo Google luôn có nguồn dữ liệu phong phú, cập nhật và phù hợp nhất để trả lời cho các truy vấn tìm kiếm.
Googlebot hoạt động như thế nào?
Googlebot hoạt động theo cơ chế:
- Bắt đầu từ một danh sách URL đã biết (ví dụ từ sitemap, backlink, hoặc dữ liệu trước đó).
- Truy cập từng URL, đọc nội dung và tìm kiếm các liên kết mới.
- Lưu trữ thông tin và cập nhật dữ liệu vào chỉ mục của Google (index).
Để tối ưu khả năng crawler truy cập trang web, việc xây dựng sitemap hợp lý, tối ưu tốc độ tải trang và hạn chế lỗi server là những yếu tố then chốt mà quản trị viên cần đặc biệt lưu ý.
Quá trình Google thu thập dữ liệu (Crawl) diễn ra như thế nào?
Quá trình Google thu thập dữ liệu (crawl) không phải là hành động diễn ra ngẫu nhiên. Thay vào đó, nó được thực hiện theo một quy trình khoa học, với nhiều yếu tố ảnh hưởng đến việc một trang web được crawl nhanh hay chậm.

1. Google tìm thấy URL mới như thế nào?
Google bắt đầu quá trình crawl từ một danh sách các URL đã biết, được gọi là “seed list”. Danh sách này có thể bao gồm:
- Các URL đã được crawl trước đó.
- Các URL mới được phát hiện thông qua sitemap.
- Các URL được tìm thấy qua các liên kết nội bộ hoặc backlink từ các trang khác.
- Các URL gửi lên thông qua công cụ Google Search Console.
Ngoài ra, khi các website mới được tạo hoặc cập nhật, nếu có liên kết từ các trang đã được Googlebot crawl, bot sẽ nhanh chóng phát hiện và thu thập các trang này.
2. Cách Googlebot quyết định trang nào cần crawl
Googlebot không thu thập toàn bộ internet cùng lúc. Thay vào đó, Google sử dụng các thuật toán thông minh để quyết định:
- Mức độ quan trọng của trang web (dựa vào PageRank, chất lượng nội dung, số lượng backlink…).
- Tính mới mẻ hoặc thay đổi của nội dung.
- Nguồn lực hệ thống và crawl budget (ngân sách crawl) dành cho website đó.
- Yêu cầu từ phía chủ website thông qua các chỉ dẫn như Robots.txt, thẻ Meta Robots hoặc HTTP Headers.
Trang web càng uy tín, nội dung càng được cập nhật thường xuyên thì Googlebot càng ưu tiên crawl nhiều hơn và nhanh hơn.
3. Tần suất crawl và yếu tố ảnh hưởng
Không phải tất cả các trang đều được crawl với tần suất như nhau. Một số trang tin tức nổi tiếng có thể được Googlebot ghé thăm hàng phút, trong khi những blog nhỏ, ít cập nhật có thể vài ngày, thậm chí vài tuần mới được crawl lại.
Các yếu tố ảnh hưởng đến tần suất crawl bao gồm:
- Mức độ cập nhật nội dung.
- Mức độ phổ biến và uy tín của website.
- Tốc độ phản hồi server (nếu trang tải quá chậm, Google sẽ giảm crawl rate).
- Cấu trúc liên kết nội bộ rõ ràng, dễ hiểu.
4. Crawl budget là gì và tại sao lại quan trọng?
Crawl budget là lượng tài nguyên mà Googlebot phân bổ để crawl một website trong một khoảng thời gian nhất định. Nếu website quá lớn, nhiều URL, hoặc server phản hồi chậm, crawl budget có thể bị tiêu hao lãng phí, khiến nhiều trang quan trọng không được thu thập dữ liệu.
Một số yếu tố ảnh hưởng đến crawl budget:
- Số lượng URL hợp lệ và giá trị.
- Số lượng lỗi trang (404, 500, chuyển hướng lỗi).
- Server tốc độ cao và ổn định sẽ giúp Googlebot crawl nhiều hơn.
Tối ưu crawl budget là cực kỳ cần thiết, đặc biệt với các website lớn có hàng nghìn URL.
Nếu bạn vẫn chưa hiểu rõ về quá trình này của Google, bạn có thể tham khảo thêm tại bài viết Crawl là gì? Googlebot làm việc như thế nào để khám phá website của bạn? Của Markdao để khám phá sâu hơn nhé!
Cách tối ưu website để Google crawl hiệu quả hơn
Muốn website được Google thu thập dữ liệu nhanh chóng và đầy đủ, bạn cần chủ động tối ưu ngay từ cấu trúc đến kỹ thuật vận hành. Dưới đây là những chiến lược quan trọng giúp cải thiện hiệu quả crawl:
- Tạo và cập nhật Sitemap XML
Sitemap XML là bản đồ chỉ dẫn giúp Googlebot hiểu cấu trúc website và nhanh chóng phát hiện các trang mới hoặc đã thay đổi.

- Đảm bảo sitemap được cập nhật tự động khi có bài viết mới.
- Loại bỏ các URL lỗi 404, 500 khỏi sitemap.
- Gửi sitemap lên Google Search Console để đảm bảo Google nhận diện đúng nội dung.
- Tối ưu hóa Robots.txt
Robots.txt là tệp chỉ dẫn cho crawler biết những phần nào trên website được phép hoặc không được phép thu thập dữ liệu.
- Kiểm tra kỹ file robots.txt để không vô tình chặn Googlebot truy cập các trang quan trọng.
- Chỉ nên chặn những phần không cần thiết như trang admin, giỏ hàng, tài nguyên phụ trợ.
- Tăng tốc độ tải trang (Page Speed)
Googlebot ưu tiên crawl những website có tốc độ tải trang nhanh vì tiết kiệm tài nguyên hệ thống.
- Tối ưu hình ảnh (nén, chọn định dạng phù hợp).
- Sử dụng cache trình duyệt và giảm thiểu mã JavaScript, CSS.
- Đầu tư vào hosting chất lượng cao hoặc dùng CDN để cải thiện tốc độ toàn cầu.
- Xây dựng liên kết nội bộ (Internal Link) hợp lý
Liên kết nội bộ giúp Googlebot di chuyển dễ dàng từ trang này sang trang khác, đồng thời xác định được cấu trúc và mối quan hệ nội dung trên site.
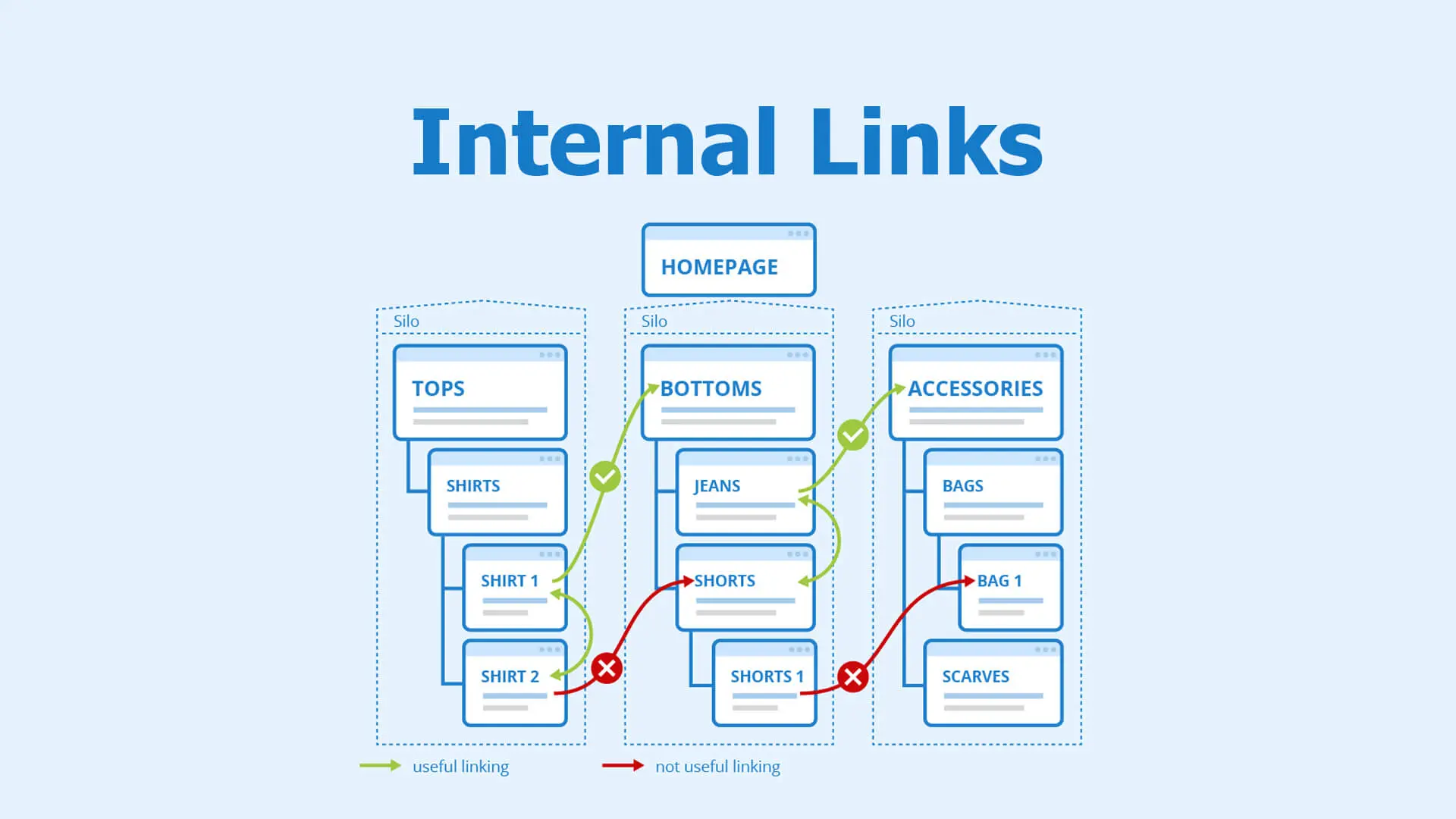
- Tạo hệ thống internal link rõ ràng, có logic.
- Ưu tiên liên kết đến những trang quan trọng để tăng tần suất crawl.
- Tránh liên kết đến trang lỗi hoặc redirect không cần thiết.
- Sửa lỗi thu thập dữ liệu
Theo dõi thường xuyên Google Search Console để phát hiện và xử lý:
- Lỗi 404 (không tìm thấy trang).
- Lỗi server 5xx.
- Vấn đề chuyển hướng lỗi hoặc vòng lặp redirect.
Xử lý sớm các lỗi này giúp Googlebot không bị “lãng phí crawl budget” vào những trang không cần thiết.
- Đăng tải nội dung mới đều đặn
Google ưu tiên crawl những website có lịch đăng nội dung mới thường xuyên.
- Duy trì tần suất cập nhật nội dung đều đặn: bài viết blog, tin tức, sản phẩm mới.
- Cập nhật hoặc làm mới các bài viết cũ để tăng “tín hiệu thay đổi” cho Googlebot.
Một số lỗi khiến Google không thể Crawler Data website của bạn
Mặc dù Googlebot được thiết kế rất thông minh, nhưng nếu website của bạn gặp phải những vấn đề nghiêm trọng trong cấu trúc hoặc kỹ thuật, quá trình crawl dữ liệu vẫn có thể bị gián đoạn. Dưới đây là những lỗi phổ biến nhất, kèm theo phân tích chi tiết để bạn hiểu và khắc phục triệt để.
1. Sai lầm trong tệp Robots.txt và thẻ Meta Robots
Tệp Robots.txt đóng vai trò như “cổng gác” cho phép hoặc ngăn Googlebot truy cập vào các phần khác nhau trên website. Tuy nhiên, nhiều quản trị viên web mắc sai lầm nghiêm trọng như:
- Chặn toàn bộ website (Disallow: /) hoặc chặn nhầm các thư mục quan trọng như /blog/, /product/.
- Không cho phép Googlebot truy cập vào file JavaScript hoặc CSS, gây ảnh hưởng đến khả năng render trang.
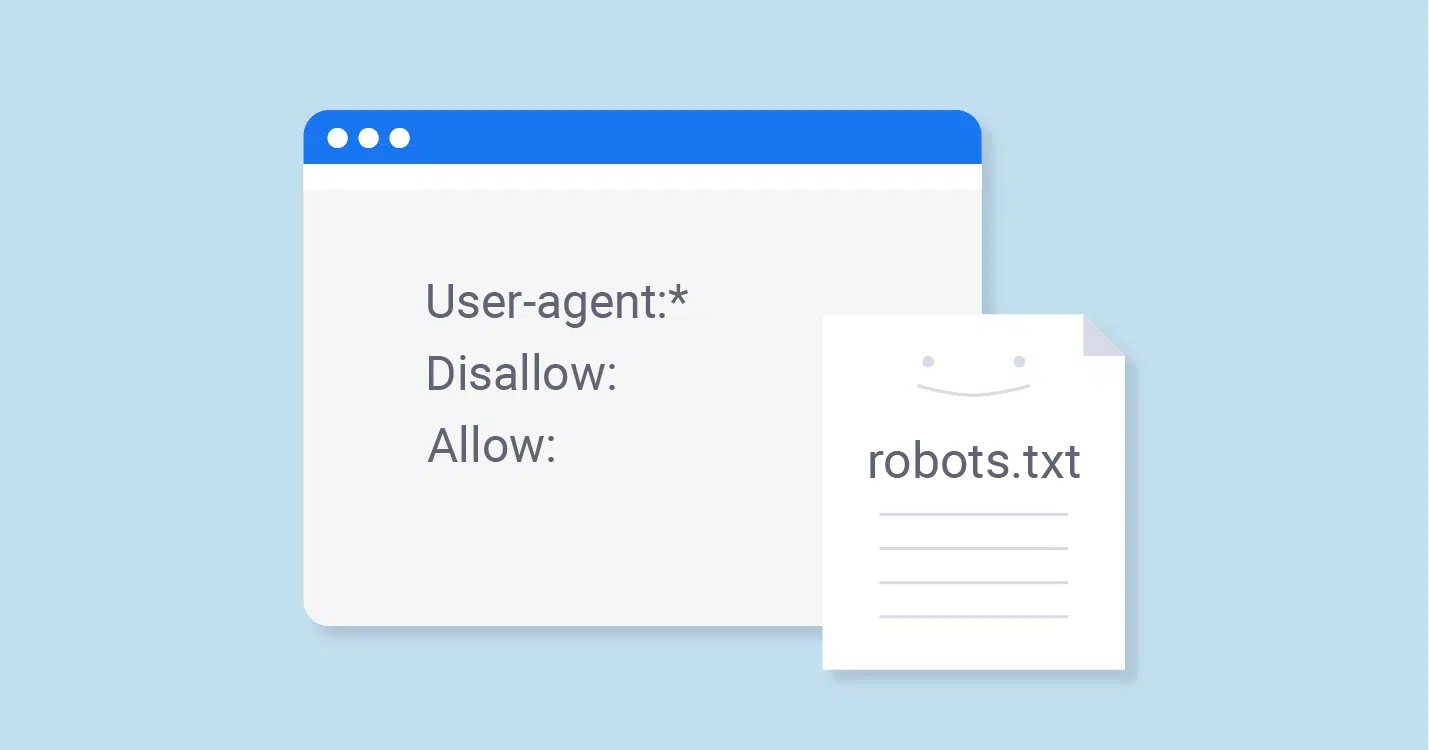
Ngoài ra, việc cài đặt thẻ Meta Robots sai trên từng trang cũng khiến Googlebot không thu thập được dữ liệu. Việc gán noindex, nofollow bừa bãi sẽ khiến Google bỏ qua các trang vốn dĩ có giá trị SEO cao.
Giải pháp: Bạn nên kiểm tra robots.txt bằng công cụ kiểm tra URL của Google Search Console, đồng thời rà soát các thẻ meta robots để đảm bảo chỉ những trang không quan trọng mới bị chặn hoặc không index.
2. Server lỗi và tốc độ tải trang kém
Googlebot cần một hệ thống máy chủ phản hồi nhanh và ổn định để crawl website hiệu quả. Nếu website của bạn thường xuyên gặp lỗi máy chủ (5xx error) hoặc tốc độ tải quá chậm, bot có thể:
- Tự động giảm tần suất crawl.
- Bỏ qua việc thu thập dữ liệu trên một số trang.
- Thậm chí, trong trường hợp xấu, đánh giá website có trải nghiệm người dùng thấp.
Các nguyên nhân phổ biến dẫn đến vấn đề này bao gồm: hosting yếu, cấu hình server không tối ưu, mã nguồn website cồng kềnh hoặc thiếu hệ thống cache phù hợp.
Giải pháp:
- Đầu tư vào hosting hoặc VPS có chất lượng ổn định.
- Tối ưu hình ảnh, giảm thiểu mã JavaScript, CSS nặng.
- Cài đặt bộ nhớ đệm (caching), dùng CDN để phân phối nội dung nhanh hơn toàn cầu.
3. Vấn đề về cấu trúc URL và liên kết nội bộ
Website có cấu trúc URL lộn xộn, quá dài, chứa nhiều tham số khó hiểu hoặc không có logic sẽ khiến Googlebot khó xác định các trang chính yếu cần crawl trước.
Ngoài ra, liên kết nội bộ yếu, rối rắm hoặc chứa quá nhiều link hỏng (404, redirect lỗi) cũng làm Googlebot lãng phí crawl budget, dẫn đến việc thu thập dữ liệu kém hiệu quả.
Giải pháp:
- Thiết kế URL ngắn gọn, có chứa từ khóa chính, dễ đọc với cả bot lẫn người.
- Xây dựng hệ thống liên kết nội bộ rõ ràng, theo sơ đồ hình cây (silo structure) để định hướng Googlebot dễ dàng.
- Thường xuyên kiểm tra và sửa chữa các liên kết nội bộ lỗi bằng công cụ như Screaming Frog, Ahrefs hoặc Search Console.
4. Nội dung dựa quá nhiều vào JavaScript
Ngày nay, nhiều website xây dựng giao diện và nội dung chính dựa trên JavaScript. Dù Google đã cải thiện khả năng xử lý JavaScript, nhưng không phải lúc nào Googlebot cũng có thể render đầy đủ trang web như người dùng thật.
Điều này khiến những nội dung quan trọng nằm trong các script không được phát hiện và index, làm giảm khả năng SEO toàn diện.
Giải pháp:
- Ưu tiên sử dụng Server Side Rendering (SSR) để nội dung được tải ngay từ server.
- Đảm bảo những phần quan trọng nhất của nội dung (tiêu đề, mô tả, text chính) xuất hiện trong HTML gốc, không phụ thuộc hoàn toàn vào JavaScript.
Việc nhận diện và khắc phục các lỗi cản trở quá trình crawl của Google không chỉ giúp website bạn được index nhanh và đầy đủ hơn, mà còn trực tiếp tác động đến hiệu quả SEO tổng thể. Hãy coi mỗi lỗi kỹ thuật như một điểm nghẽn cần tháo gỡ để website của bạn thực sự “mở cửa” cho Googlebot truy cập dễ dàng và liên tục.
Kết luận
Hiểu rõ về quá trình crawl dữ liệu của Google không chỉ giúp bạn nắm bắt cách công cụ tìm kiếm “đọc” website, mà còn mở ra cơ hội tối ưu hóa SEO từ gốc. Một website được crawl hiệu quả sẽ được index nhanh, xếp hạng cao và tiếp cận người dùng rộng rãi hơn.
Đừng để những lỗi kỹ thuật nhỏ trở thành rào cản lớn. Hãy chủ động tối ưu website, từ cấu trúc URL, tốc độ tải trang đến tệp robots.txt, để Googlebot dễ dàng thu thập dữ liệu và đánh giá đúng giá trị nội dung của bạn.


{kind=link}